[翻訳] Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
“Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos” の翻訳/解説を行います。まだ訳しきれてないですけど,もう書くのめんどくさいので公開します。
概要/はじめに
背景/従来手法
- カメラは他のセンサに比べ安価であるため,RGBカメラからの深度とエゴモーション1推定は有益である。
- 教師あり学習による単一画像からの深度推定は成功している2。しかし,教師あり学習は,高価な深度センサーが必要であり,センサーのノイズが発生する問題がある。
- 多くの教師なしの画像から深度推定する手法が提案されており,教師なしの深度推定モデルはセンサー教師ありのモデルよりも精度が高いことが実証されている。精度が良い要因は,センサーの画素の欠落やノイズがないことである。
- ステレオカメラや独立したオプティカルフロー推定により,精度向上が行われた。
提案手法
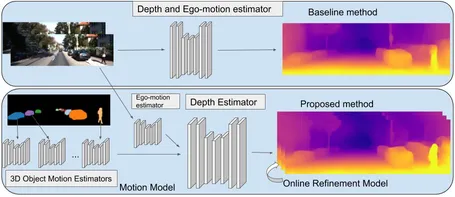
- 単眼RGB動画像から深度とエゴモーション推定を教師なし学習で実現する。
- キャリブレーションしていない単眼動画から学習できる。
- Modeling Object Motion:画像中の物体の動きをモデル化し,学習に幾何学的構造を導入する。
- Imposing Object Size Constrains:物体サイズによる正則化する。
- Online-Refinement:推論実行時に,オンラインにパラメータをチューニングし,未知の領域に適応する。
- 提案する手法は,モーション処理を含め,すべて最先端の手法よりも優れている。
- 結果は,ステレオカメラを利用したものと同等の品質であった。
- 物体の動きを多く含む(ダイナミックな)動画の深度推定を大幅に改善した。
- ソースコードはここにある。
- Geforce 1080tiでバッチサイズが4と1でそれぞれ50 FPSと30 FPSの速度で実行できる。
手法
- 単眼動画からの深度とエゴモーションを教師なしで学習する。
- 物体の動きをモデル化することで,動的なシーンをモデル化し,オンラインチューニングすることができる新しい手法を提案する。
- この2つのアイデアは関連していて,別々または共同で使用できる。
- 2つのアイデアを個別に説明し,さまざまな実験で有効性を示す。
問題の設定
3枚のRGB画像3と,カメラ固有行列を入力とする。深度推定ネットワークは,エンコーダ・デコーダの畳込みニューラルネットワーク(CNN)で,1つのRGB画像から密な深度画像を生成する。エゴモーション推定ネットワークは,2つのRGB画像対を入力とし,フレーム間の並進と回転パラメータを生成する。同様にも生成する。
微分可能な画像ワーピング演算子が再構築されれた番目の画像である場合,対応する深度推定結果とエゴモーション推定結果が与えられると,任意の画像をにワープできる。は変換された画像のピクセル座標から読み取りを設定してワーピングする。ここでは投影された座標である。監視信号は,次のフレームに投影されたシーンをRGB空間の実際の次のフレーム画像と比較する測光損失(photometric loss)を使用して確立される。再構築損失を使用する。
アルゴリズムのベースライン
最近の研究4により,アルゴリズムの強力なベースラインを確立する。再構築損失は,前後のフレームのいずれかから中央のフレームへのワープの最小再構築損失として計算される。提案5された
により重大なオクルージョン/ディスオクルージョン効果によるペナルティを回避できる。再構築損失に加えて,ベースラインはSSIM損失6,深度平滑損失を使用し,学習中に深さの正規化を適用する。これは,先行研究7での成功を示している。全体の損失は4つのスケールで適用される
ここではハイパーパラメータである。
モーションモデル
個々の3Dオブジェクトのモーションの予測に特化したオブジェクトモーションモデルを紹介する(図8)。事前に求めたセグメンテーションマスクによって画像を補完する。は3D空間内のオブジェクトごとの変換ベクトルを予測することを学習するようにタスクが設定される。ワープされた画像の計算は,以前の研究7のようにエゴモーションに基づく単一の投影だけでなく,適切に組み合わされる一連の投影でもある。静的背景はに基づく単一のワープによって生成されるが,セグメント化されたすべてのオブジェクトは,最初に次ににしたがってワープされた外観によって追加される。このアプローチは,オブジェクトの動きが3Dで学習され,推論で利用できるという点で,2D画像空間の動きにオプティカルフロー9または3Dオプティカルフロー10を使用した先行研究と異なる。このアプローチは,オブジェクトを3Dでモデル化するだけでなく,その場でオブジェクトの動きを学習する。これは,シーンおよび個々のオブジェクトごとに独立して深度をモデル化する原理的な方法である。
インスタンス整列セグメンテーションマスクを,シーケンス(, , )内の各潜在的なオブジェクトごとにとして定義する。静的シーンのマスクを定義し,移動する可能性のあるオブジェクトに対応するすべての画像コンテンツを削除する。一方,でのは,オブジェクトのマスクのみを返す。静的シーンのマスクは,シーケンスをエゴモーションモデル関数にフィードする前に,アダマール積(要素ごとの乗算)によってシーケンス内のすべての画像に適用される。オブジェクトの動きをモデル化するには,最初にエゴモーションの推定を適用して,ワープされたシーケンス(, , )と(, , )を取得する。深度とエゴモーションの推定値が正しいと仮定すると,画像シーケンス内の不整合は,移動するオブジェクトによってのみ発生する。移動する可能性のあるオブジェクトの概要は,既成のアルゴリズム11によって提供される(対象のデータセットのいずれでもトレーニングされていないオプティカルフロー10を使用する以前の作業と同様)。画像内のすべてのオブジェクトインスタンスについて番目のオブジェクトのオブジェクトモーション推定値は次のように計算される。
実際の3D動きベクトルは,それぞれの領域でのオブジェクトの動きの変換の前後の動きを追跡することによって取得される。これらの動きの推定値に対応して,予測された動きにしたがってオブジェクトを移動する逆ワーピング操作が実行される。最終的なワープ結果は,移動するオブジェクトからの個々のワープとエゴモーションの組み合わせとなる。すべてのワーピングは,
となり,に相当する。満たされていない領域が存在する可能性があるが,これらは最小損失計算によって暗黙的に処理される。このアルゴリズムは,推論で使用できるオブジェクトごとに個々の3Dモーションを自動的に学習する。
オブジェクトサイズの制約
先行研究5 10では,ほぼ同じ速度で前方を移動する車が,無限の深さに投影されることが多いことであると指摘された。これは,オブジェクトが動かず,ネットワークがそれを無限に遠くにあると推定した場合,再投影損失がほぼゼロになるからである。先行研究では,この重大な制限5 6 10が指摘しているが,ステレオ画像でデータセットを拡張する以外に解決策はないと考えられていた。ただし,ステレオは単眼に比べ一般的ではなく,適用性が制限される。この問題に対処する別の方法を提案する。オブジェクトを非常に近くに配置し,小さいと仮定して,オブジェクトの動きを説明する。このアイデアは,モデルにオブジェクトのスケールを学習させ,3Dでオブジェクトをモデル化できるようにすることである。車の場合,(は焦点距離,は実次元での事前の高さ,はピクセル単位のセグメンテーションの高さ)を使用して,セグメンテーションマスクとカメラの固有値が与えられた場合に,おおよその深度推定を取得できる。実際には,そのような制約を手作業で推定しないために,追加の入力を必要とせずに,ネットワークにすべての制約を同時に学習させる。各オブジェクトのスケールで損失項を定義する。が任意のオブジェクトのカテゴリIDを定義し,が各カテゴリIDの前の学習可能な高さであるとする。を深度マップ推定,を対応するオブジェクトアウトラインマスクとする。次に,損失
は,セグメント化されたすべてのオブジェクトが無限の深さに縮退することを防ぎ,ネットワークに妥当な深さだけでなく,一致するオブジェクトの動きの推定値も生成される。中間フレームの平均推定深度であるでスケーリングして,事前確率と深度予測範囲を共同で縮小することにより,些細な損失削減の潜在的な問題を軽減する。これは3Dの完全な単眼トレーニングセットアップで一般的な変性症例に対処する方法である。この制約はモデリング定式化の不可欠な部分であるため,モーションモデルは最初からでトレーニングされる。ただし,この追加の損失は,すでにトレーニングされたモデルに適用するときに誤った深度推定値を正常に修正できることを確認した。移動するオブジェクトの深度を修正することで機能する。
テスト時間の絞り込みモデル
単一フレームの深度推定器を持つことで,幅広い適用性を持つ。連続する予測は不整合または不連続であるため,画像で連続的な深度推定を実行する場合にコストがかかる。これらは,2つの主要な問題によって引き起こされる。
- モデルに実スケールとの関連がないため,隣接するフレーム間でスケーリングが一致しないこと。
- 深度予測の時間的一貫性が低いこと。
オンライン最適化を効果的に実行することでこれらを解決し,推論を実行しながら学習を継続すること手法を提案する。これにより,非常に限られた時間分解能でも,定性的および定量的に深度予測の品質を大幅に向上できる。よって通常は無視できる1フレームの遅延で,メソッドをリアルタイムでオンラインで実行できる。オンラインでの改善は,モデルを動的に微調整するに対して実行される。は,オンラインチューニングの活用と,過学習を防ぐこととの適切な妥協点を決定する。オンライン改善アプローチは,すべてのモデルに適用できる。
実験結果
深度推定,エゴモーション推定,転移学習についての以下に示すデータセットを用いて評価実験を行う。
- KITTI:深度推定,エゴモーション推定のベンチマークに使用する。
- Cityscapes:微調整することなくトレーニングや転移学習ができるかの評価に使用する。
- Fetch Indoor Navigation:転移学習により,屋内ナビゲーションでの評価に使用する。
KITTIでの結果
ベースラインおよび先行研究に比べ大幅に推定精度を改善することができた(図と表は省略)。さらに,単眼の推定にもかかわらず,ステレオによる推定に近い精度が得られた。
Cityscapesでの結果
提案されたアプローチの絶対相対誤差がからに大幅に改善されていることから,この方法の利点を明確に示している。これは,最新の誤差のコンテキストでとくに印象的であった。また,モーションモデルとリファインメントモデルの両方によって,個別に,または共同で改善が達成されていることがわかる。
結論と今後の課題
この論文では,個々のオブジェクトの動きを3Dでモデル化することにより,単眼の深度とエゴモーションの問題に対処する。また,適当な動画で学習を適応させ,新しいデータセットまたは環境に応用できるオンライン改良手法を提案した。このアルゴリズムは,確立されたベンチマークで最高のパフォーマンスを実現し,動的なシーンに対してより高品質の結果を生成を実現した。将来的には,より多くの時間情報を組み込むために,より長いシーケンスにリファインメント方法を適用を考えている。今後の作業では,提案された深度とエゴモーションの推定方法によって可能になる完全な3Dシーンの再構築にもできると考える。
文献
- Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
- struct2depth
脚注
-
カメラ(視点)の移動量のこと。 ↩
-
Eigen, Puhrsch, and Fergus 2014; Laina et al. 2016; Wang, Fouhey, and Gupta 2015; Li, Klein, and Yao 2017 ↩
-
簡単のために,3枚で説明する。4枚以上でも可能である。 ↩
-
Zhou et al. 2017; Godard, Aodha, and Brostow 2018 ↩
-
Zhou et al. 2017; Godard, Aodha, and Brostow 2017; Wang et al. 2018 ↩ ↩2
-
図は論文から引用。 ↩
-
Yin. 2018 ↩
-
He et al. 017 ↩